SQLAlchemy and Race Conditions: Follow Up on Commits and Flushes
In an earlier post, I talked about my adventures in creating a get_one_or_create() function for SQLAlchemy to use with Flask and Postgres.
There was an excellent question asked in the comments about weather session.flush() could be used on line 13 instead of session.commit(). I didn't fully understand the answer, but explained that I had landed on this for safety of efficiency. The author of SQLAlchemy also echoed that it's not a simple answer. I spent some time with a small test app on Heroku to figure out how this all works, and what the best approach really was.
For quick reference, the solution I landed on was:
def get_one_or_create(session, model, create_method='', create_method_kwargs=None, **kwargs): try: return session.query(model).filter_by(**kwargs).one(), True except NoResultFound: kwargs.update(create_method_kwargs or {}) created = getattr(model, create_method, model)(**kwargs) try: session.add(created) session.commit() return created, False except IntegrityError: session.rollback() return session.query(model).filter_by(**kwargs).one(), True
Important Note: The app that I used for testing can be referenced in this repo on GitHub, and I am using Python 2.7.4, with Flask 0.10.1, Flask-SQLAlchemy 1.0, SQLAlchemy 0.9.2, and Postgres 9.3.2 running on Heroku. Many of the ways in which SQLAlchemy works rely heavily on the configuration, so if you are using a different se up, I urge you to take this with a grain of salt and as useful ideas for testing your own setup.
session.commit() vs session.flush()
At the surface, the difference between these two operations is fairly straight forward.
A call to session.commit() takes any new objects or changes to existing objects in the session and attempts to write them to the database. If a new object has a key or other attribute that the database creates, that is created during the write and in turn populated on the object in the session.
A call to session.flush() however, only populates our objects, but does not write to the datastore yet. (I've italicized only because I am about to show that it actually does more than that.)
So what happens if I have an object with a unique constraint on an attribute, and in two different sessions/processes/Heroku dynos create the object with the same value for that attribute, and then try call session.flush()? Since neither value has been written to the database, we don't expect an IntegrityError. But we also ideally wouldn't want this to roll by without issue. So what does happen?
I created a small test Flask app and deployed it to Heroku. I then spun up two sessions of iPython, also on Heroku, imported our Game object and attempted to violate our unique constraint on provider_game_id. Check out what happened:
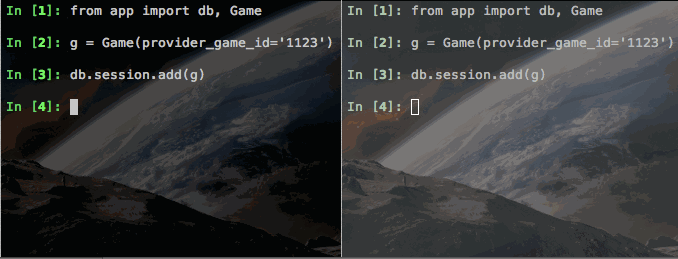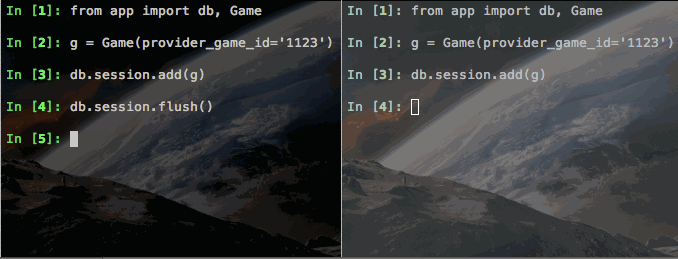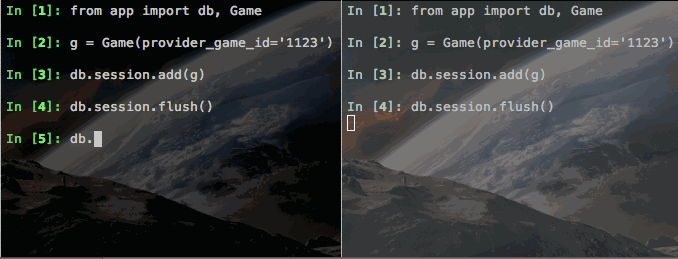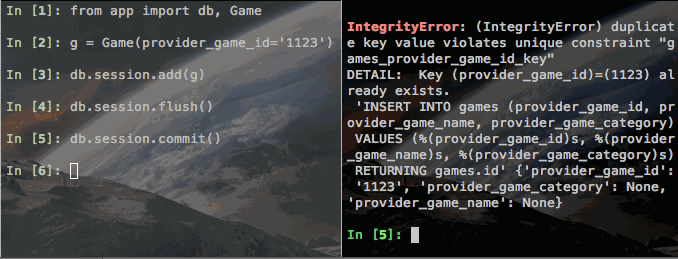
Notice how the first call to session.flush() (on the left) works just fine. But then the second call (on the right) hangs - note this is a completely different Heroku dyno. The only connection these two have are the Postgres database. So (at least with Postgres), session.flush() is able to use Postgres to stage our value, but not write it yet. That's pretty rad.
Changing get_one_or_create()
This will work with the get_one_or_create() function above by replacing line 13 (as suggested in the comment) as so
def get_one_or_create(session,
model,
create_method='',
create_method_kwargs=None,
**kwargs):
try:
return session.query(model).filter_by(**kwargs).one(), True
except NoResultFound:
kwargs.update(create_method_kwargs or {})
created = getattr(model, create_method, model)(**kwargs)
try:
session.add(created)
session.flush()
return created, False
except IntegrityError:
session.rollback()
return session.query(model).filter_by(**kwargs).one(), True
In this case, if one process creates an object, and a second process attempts to create the same object (i.e. overlapping in a unique constraint), the second process will stall at the session.flush(). If the first process eventually calls session.commit(), the second process will raise the IntegrityError, as expected, and then be able to actually query the object. If, instead, it dies or or whatever other reason doesn't call session.commit() but it's session clears, then the second session will resume and return the newly created object.
My original fear was that the session.flush() could pass in both cases before the session.commit() was called, and then when the second session.commit() (or a session.flush()) the IntegrityError would raise out of the context of the get_one_or_create() and we wouldn't (easily) know which object to get instead of create. This isn't the case.
There is likely interesting economics in the balance between batching your commits (less frequent large commits are generally more efficient than frequent small commits) and the probability of a process stalling on the session.flush() (and hence the expected loss of computation from that stalling). Generally, though, I would opt towards committing whenever a new object is created. There are some times, however, that you may want slightly more delicate control, which makes the above approach superior to the originally proposed solution.
Consider a new object GameStat, which for every Game this object must exist (it's a pretty contrived example, but in other situations this relation can come up). When doing web programming (or really any program), you should assume that at any point any process could die. If the GameStat object must exist for every Game, then we can delay our call to session.commit() until both objects are been initialized. In this relatively small amount of time, it's unlikely that we will get an overlap, but if we do, the call to session.flush() shouldn't stall the process for very long.
UPDATE: I've updated using a {} as a default value in the function as this is typical Python gotcha. Thanks for the comment, Nigel! If your curious about this gotcha, check out this StackOverflow question and this blog post.